How Far Can You Push Excel with Regex?
- Oct 15, 2025
- 8 min read

If you’ve spent any time in Excel, you’ll know the struggle of working with a messy dataset. You’ve got an inventory list with product codes buried in long strings of text; there’s customer notes where the phone number might be formatted five different ways; and you have a column of web links where you need to extract only the unique tracking ID buried deep in the URL. These are the sort of routine tasks that can easily turn into hours of frustrating, error-prone, manual work.
Regular Expressions (RegEx) are designed to solve this exact problem. They allow us to define complex patterns in text data leading to clean and simple, data extraction, validation and processing.
In the world of business, analytics, and data, Excel is perhaps the most divisive tool. It has a diehard fanbase who will defend it to the end of the Earth, yet, it’s criticized by others for not being a “proper data science tool”: slow, error prone, and incapable of facilitating any complex data handling tasks. In this article, we’ll see how using Regular Expressions can bridge the gap between lowly spreadsheet software and a professional data analysis pipeline – at least when it comes to text data. We’ll explore some of the theory behind Regular Expressions and show how we can implement this technique to substantially improve the efficacy and efficiency of text data processing right inside of Excel.
Types of Formal Grammar
In my previous article, The Hidden Mathematics of Language, I introduced the idea of formal grammars. Somewhat akin to the grammar rules for natural language or the syntax rules for a programming language, formal grammars consist of systems of rules that define which combinations of symbols form valid sentences in a language. These production rules describe how smaller components combine into larger structures, such as words into clauses or clauses into sentences. A language, is the set of all possible sentences that the grammar rules can produce.
There are 4 main, distinct types of grammar, each with a different level of expressiveness, and each corresponding to a different class of machine that is capable of recognising it. These machines are sometimes known as automata. For today, we’re just going to focus on Regular Grammars.

Above. The Chomsky Hierarchy for formal grammars.
Regular Grammars and their Equivalent Forms
Regular grammars, are the simplest type of formal grammar. They can be represented using set-definitions, sets of production rules, or regular expressions. Regular languages can contain sentences including:
Repeated symbols: {“a”, “aa”, “aaa”, …}
Optional Symbols: {“a”, “aa”, “aaa”, “ba”, “baa”, “baaa” …}
Alternation: {“a”, “ab”, “aba”, “abab”, …}
Fixed-order sequences: {“ac”, “abc”, “abbc”, “abbbc”, …}
or any combination of the above.
This makes them useful for recognising – or parsing – strings such as ID numbers, postcodes and email addresses. The automata for a regular grammar is called a Finite State Machine (FSM).
Finite State Machines

These automata parse strings by moving from state to state. We start at the start state, S0, then read through the input string, choosing the next state based on the character being read. If the end state, S5 in the FSM above, is reached, then the parse was successful and the string is valid within the language. If the machine reaches a state from which it cannot transition out of, then the parse has failed and the string is invalid.
The FSM above is designed to recognise precisely 2 strings, abdca,aca. There are 2 possible routes we can take from S0 to S5 giving us the 2 possible strings that can be parsed. If you tried to parse the string “abca” using this FSM, we would get to state S2 and the parse would fail as the next character being read is not a “d”.
Finite State Machines have no memory so the decision about which characters can be parsed next is determined only by the current state. As a result, regular grammars cannot represent recursive structures — think pairs of nested brackets. With no memory, the machine has no knowledge of how many open brackets have come before, and therefore has no way of knowing how many closing brackets are required in order to parse a valid expression. We could design a machine that requires a finite, known number of brackets, but it is not possible to parse sentences with an unknown number of bracket pairs.
Regular Expressions
As mentioned, regular grammars are part of a wider landscape of formal grammars. Other types allow for greater expression, but come with their own limitations. The beauty of a regular grammar is that it can be represented by a regular expression.
A regular expression is another way to describe the set of sentences that can be parsed by a regular grammar. Let’s take a look at some basic syntax to get us started:

We can write a regular expression by combining these symbols to indicate which characters we should expect in a valid string. The quantifiers refer to the character (or group of characters if using brackets) directly preceding. As such,
“b” means we should expect a “b” in the string
“b?” means there may or may not be a “b”
“b+” means we should expect at least one “b”
“b*” means we should expect any number of “b”s (including none at all!)
Where we have multiple characters in the string,
“ab” means we should expect an “a” followed directly by a “b”
“ab+” means we will have an “a” followed by at least one “b”
“(ab)+” means we should expect at least one “ab” pair (so “abab” would also be allowed”)
“bb*” is equivalent to writing “b+”
Using this method, we can construct Regex expressions such as
“ab?c*\d”
…which will be able to parse strings including “abc1”, “ac4”, “a9”, “acccc6”, “abcc0” – an “a”, an optional “b”, any number of “c”s and then a digit, 0-9.
Equivalence of the two forms
An equivalent, FSM for this Regex expression could look like this:

You may notice the addition of the ϵ between S2 and S3, and S1 and S3. This allows the machine to transition between states without reading a symbol from the input string.
A Finite State Machine for a given grammar may not be unique. There can be multiple different machines that parse the same set of sentences. A well designed FSM should be deterministic, meaning there are never multiple options for which state should be chosen next. It is always possible to transform a non-deterministic FSM into a deterministic one using the Subset Construction Algorithm.
In the example above, in state S1, the machine could either parse a b and move to state S2, or move directly to S3 without reading a character. The machine has a choice and hence, is non-deterministic. We can construct an equivalent machine that will recognise precisely the same set of sentences, but that is deterministic:

We are never presented with a choice over which state to transition into next. There are no ϵ transitions, and no states with multiple outbound arrows of the same label. Therefore, this machine is deterministic.
Additional Syntax
To really make use of the power of regular expressions, we need a little more notation:

Regex in Excel
Excel allows us to work with regex natively through the use of 3 different functions:
REGEXTEST(text, pattern, [case_sensitivity])
Tests if the text (or a substring of the text) matches the regex pattern
REGEXEXTRACT( text, pattern, [return_mode], [case_sensitivity])
Extracts a substring that satisfies the regex pattern
return_mode:
0: first match,
1: all matches,
2: returns each match separated out into capturing groups (more on this later)
REGEXREPLACE(text, pattern, replace, [occurrence], [case_sensitivity])
Replaces the substring matching the given pattern with the replacement text provided
The occurrence number indicates which match should be replaced if there are multiple. If not provided, replaces all instances.
Excel also provides the additional quantifier of {n,m} which indicates that between n and m (inclusive) of the previous symbol should be matched. If m is left blank, then it will match any number greater than or equal to n.
So what can we do with it?
Removing non-alphanumeric characters
Using REGEXREPLACE, we can find all occurrences of non-alphanumeric characters and replace them with an empty string – effectively removing them from the text.
=REGEXREPLACE(A1,"[^A-Za-z0-9]","")
Removing double spaces
Similarly, we can search for all occurrences of double (or more) spaces and replace them with a single space.
=REGEXREPLACE(A1," {2,}"," ")
(You might have to take my word for it with the trailing spaces)
Extracting or validating email addresses
We can search for a valid email address format by looking for:
A set of characters, underscore or other acceptable character
An @ symbol
Another set of characters
A ‘.’
And then another set of characters of length at least 2
=IF(REGEXMATCH(A1,"[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}"),"Valid","Invalid")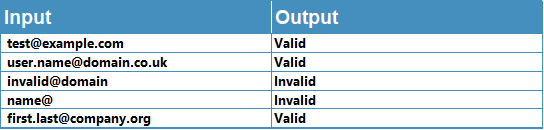
Extracting a domain from a URL
=IFERROR(REGEXEXTRACT(A1,"https?://(?:www\.)?([^/]+)"), "")
Extracting a product code or ID
We can search for IDs or codes in a specific format, in this case, a set of characters of length at least 2, a ‘-‘ and then at least one number.
=REGEXEXTRACT(A1,"[A-Z]{2,}-\d+")
Extracting data from between delimiters
We can search for text embedded between 2 given delimiters, in this case ‘[‘ and ‘]’.
=IFERROR(REGEXEXTRACT(A1,"\[([^]]+)\]", 2), "")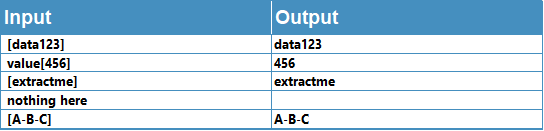
See the section below on capturing groups for details on the additional parameter “2” in the formula above.
Parsing JSON to extract a specific field
Parsing JSON in Excel is difficult using traditional tools. Regex greatly simplifies this as we can search for ‘ :” . . . “, ‘.
=IFERROR(REGEXEXTRACT(A1,"""fieldName"":\s*""([^""]+)"""), "")
Parsing JSON to extract all fields (multiple matches)
Taking this one step further, we can extract multiple matches into a #SPILL range and handle them separately. This is useful if your JSON always returns arguments in the same, known order.
=IFERROR(REGEXEXTRACT(A1, ":\s*""([^""]*)""", 1), "")
Data categorisation
We can neatly check the contents of strings for some given keywords and categorise the text accordingly.
=IFS(REGEXMATCH(A1,"error|fail"),"Error",REGEXMATCH(A1,"success|pass"),"Success",TRUE,"Other")
Capturing Groups
When we enclose part of a regular expression in brackets, we’re creating capturing groups. E.g:
(∖d+),
([A−Za−z]+),
(∖w+)
Each group stores whatever substring matches that portion of the regex pattern, in the order in which they appear. During the REGEXREPLACE() function, we can refer back to these captured groups using “$1”, “$2”, “$3”, etc… .
=REGEXREPLACE("Doe, John", "(\w+), (\w+)", "$2 $1")
>>> John DoeIt’s worth noting that is a feature of Excel, rather than a mechanism built into regular grammars themselves. Regardless, it’s quite useful for reformatting text data where you don’t know the exact contents or length.
Removing duplicate words
We can also use this technique to search for multiple consecutive occurrences of the same word and remove them.
=REGEXREPLACE(A1,"\b(\w+)(\s+\1\b)+","$1")
Text transformation / reformatting
…and we can add characters in-between the groups to put them into a required format.
=REGEXREPLACE(A1,"(\d{4})(\d{4})(\d{4})(\d{4})","$1-$2-$3-$4")
Beyond Regular Grammars: Context Sensitive Data Extraction
While these are “Regex” functions, Excel doesn’t seem to have stayed within the bounds of a regular language. But we’re not complaining; the lookahead and lookbehind assertions are quite useful.
As the name suggests, these constructs let a regular expression match text based on its surrounding context, For instance:
(?<=Score:∖s∗)∖d+ matches a digit only if it’s preceded by Score:
∖w+(?=∖.jpg) matches a word only if it’s followed by .jpg
This ability takes us out of the realm of regular grammars, and into the world of Context Free or Context Sensitive ones; we’re matching based the specified, context, elsewhere in the text. You can also think of it as introducing a form of memory or dependency which would exceed of the capabilities of a finite state machine.

Obfuscating sensitive data
We can look for characters that have a given number of characters ahead or behind them to make sure we obscure the data, but leave some visible.
=REGEXREPLACE(A1,"(?<\w{2})\w(?\w{2})","*")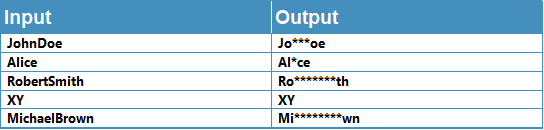
Wrapping up
Regex brings a surprising amount of sophistication to Excel. While some of these tasks can still be done using LEFT(), RIGHT(), MID(), etc… utilising regular expressions makes this process a lot smoother and cleaner. With just a few formulas, we can extract structured data from (almost) whatever mess you throw at it. Data validation and transformations that would have taken hours can now be done in seconds. And if you ever get stuck, sketching out a quick finite state machine can definitely help.
Excel’s new regex functions bring the logic of regular grammars into everyday data workflows. The same rules that define the behaviour of formal languages now sit quietly behind familiar formulas, letting us recognise, extract, and transform text with precision. It’s a small but meaningful shift, not because it turns Excel into something it isn’t, but because it shows how much can be achieved when old tools meet a bit of formal thinking.



Comments